
By Felix Liao, Director, Product Management – Denodo
By Mitesh Shah, Director, Cloud GTM, Alliances and Product Management – Denodo
By Kiran Singh, Sr. Partner Solutions Architect – AWS
By Parvinder Singh, Partner Solutions Architect – AWS
| Denodo |
 |
Cloud-based data storage solutions such as Amazon Redshift and AWS Lake Formation have made it easier to store and manage large amounts of data, while at the same time reducing the overall unit cost of storing data when compared with traditional on-premises solutions.
When it comes to end-user data access and reporting, however, organizations often struggle to integrate data effectively and suffer from long delays when it comes to delivering relevant data to the right users at the right time.
Problems associated with data delivery can be pinpointed to the data integration process. The issues associated with costly, time-consuming, and brittle extract, transfer, load (ETL) data pipelines are particularly acute for analytics and data science projects, where data integration can typically take up to 80% of the overall project efforts and budgets.
The reality is that most organizations have to deal with a complex, heterogeneous data environment that involves legacy and on-premises data sources. Managing and integrating all these data in a highly distributed landscape can be difficult, even for some of the most sophisticated and mature firms on the planet.
As a data integration pattern, ETL is falling short as the demand for real-time data increases and the overall data landscape continues to be more distributed and siloed. Amazon Web Services (AWS) recognizes these challenges and believes in a “zero-ETL” future.
With newly-announced capabilities such as Amazon Aurora MySQL zero-ETL integration with Amazon Redshift, AWS will speed up and simplify data integration efforts between Amazon Aurora and Amazon Redshift to help its customers move towards a Zero-ETL future.
In this post, we will discuss how data virtualization and the Denodo Platform has helped organizations transform their data integration approaches and accelerate their analytics efforts. Denodo is an AWS Specialization Partner and AWS Marketplace Seller with the Data and Analytics Competency.
Denodo Platform and Data Virtualization
The Denodo Platform and data virtualization were created from the ground up to facilitate a logical approach to data integration with minimum ETLs and data replications. By connecting the data sources and data consumers virtually via a logical layer, Denodo helps eliminate the need to move and replicate the data over and over again.
By removing hard-wired, one-to-one connections typically seen in ETL pipelines, Denodo provides organizations with incredible speed and agility as they continue to adapt to an evolving data landscape.
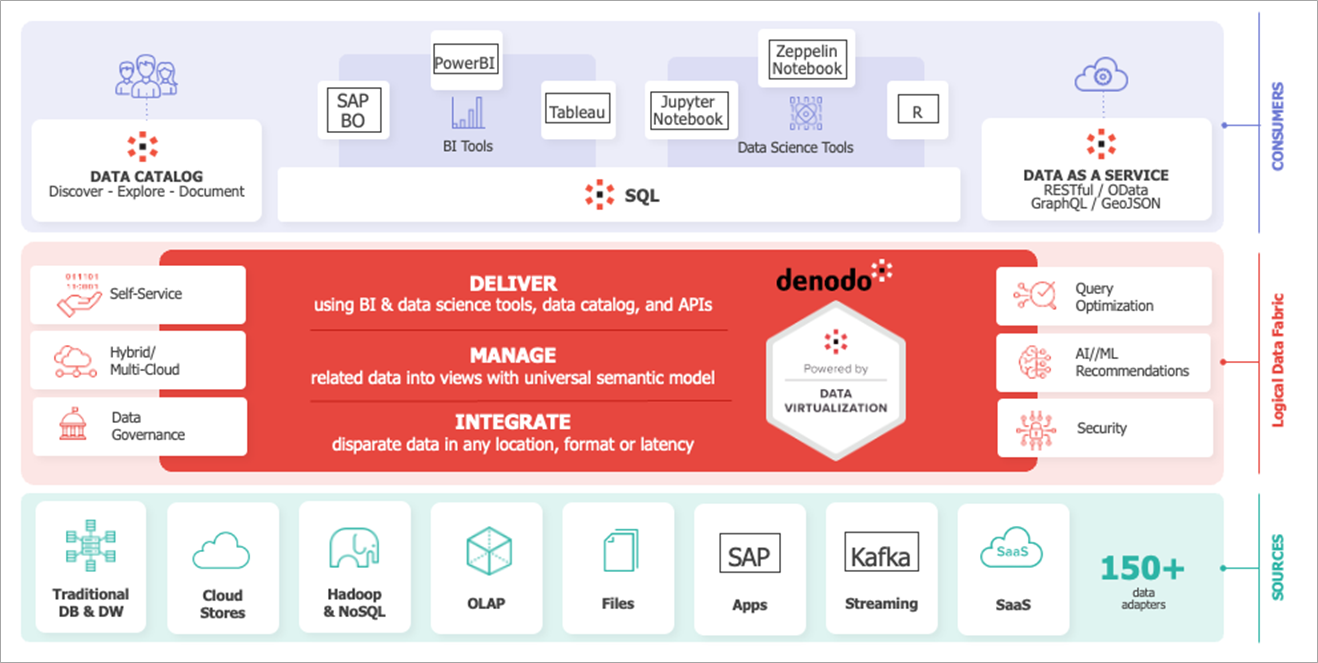
Figure 1 – Denodo Platform overview.
From a data consumption perspective, end users can easily discover and access data from a single point of access, regardless of where the underlying data comes from. They also have direct access to real-time data and the opportunity to develop their own logical data model more easily and quickly.
The abstraction provided by the data virtualization platform means Denodo can publish and expose the same data via multiple technologies and formats, including SQL (JDBC,ODBC, and Python), OData, or GraphQL APIs.

Figure 2 – AWS-based data architecture enabled by Denodo.
When deployed in a customer’s tenant on AWS, the Denodo Platform can be used to connect to Amazon Redshift, and other data repositories easily. These can also be integrated with data from external applications APIs such as Salesforce to develop detailed analytical base views focused on customer profiles.
Finally, as an Amazon QuickSight or Amazon SageMaker user, Denodo acts as a single, unified access point for all integrated data, except without the pain and headaches of building and maintaining ETL pipelines.
Integrate and Manage Data
Using the browser-based Denodo design studio applications, users can connect to 200+ data sources via a graphical user interface (GUI) that support multiple authentication mechanisms and protocols (including LDAP, AD, SAML, and Kerberos).
The Denodo Platform includes a native connector for Amazon Redshift, which can take full advantage of the Denodo query optimization engine. This means that where possible, queries and functions are pushed to Redshift for execution and that Redshift can be used as an intelligent caching engine to improve overall performance.
The process of adding a new data source is consistent and simple. Denodo has simplified the connection configuration process for end users while taking full advantage of the power and capabilities of the underlying data repository.
With an increasing trend towards data lake-based architecture and a need to integrate data lake data in a timely manner, Denodo offers integration support for data stored within an Amazon Simple Storage Service (Amazon S3)-based data lake directly.
The Denodo Platform includes an embedded massively parallel processing (MPP) SQL data lake engine, which is powered by the Presto open-source project. It allows users to manually introspect and import individual data lake files as relational table views, and provides a scalable SQL execution engine that works as a seamless part of the Denodo Platform.
AWS customers can fully leverage existing metadata already generated and stored in AWS Glue Data Catalog.

Figure 3 – Browsing and adding data lake files from Amazon S3 as data sources.
The Denodo Platform also supports data services APIs as a data source. Data scientists can use the same data configuration window to connect and ingest data from API-powered data sources. Denodo takes care of the complex tasks of authenticating and interacting with the API endpoint, as well as the processing and flattening of JSON files typically retrieved from API endpoints.
The ease and simplicity of connecting and integrating with multiple data sources via the Denodo Platform means business intelligence (BI) users and data scientists can move with speed and innovate without the pain and constraints associated with traditional, ETL-centric integration approaches.
Build and Deliver Logical Data Model
One of the most valuable things offered by the Denodo Platform and data virtualization is the speed and ease of creating new logical data views. Instead of building physical ETL data pipelines that move, replicate, and persist data during every run, Denodo allows users to develop new data views and models logically. This means new views and data models can be created more quickly without worrying about things such as data storage and data duplications.
Regardless of whether the underlying data source is Amazon Redshift, Parquet files from Amazon S3, or JSON files retrieved from a software-as-a-service (SaaS) application API, Denodo presents a consistent relational data structure that’s familiar and easy to work with. Just about any user can add new data sources and develop their own set of integrated and unified data models.
In the example below, we are developing a new sales view by joining transaction data from Amazon S3, store data from Amazon RDS for Oracle, and customer information from the Salesforce API. These logical data models can be developed quickly without any physical movement or replication of data.
When necessary, the logical model can be cached intelligently to speed up access and improve query performance. Users have full control over things such as join conditions, output columns, and group by logic, all within an easily-to-use graphical user interface (UI).

Figure 4 – Logical data model combining data from different sources.
As well as supporting joining multiple data tables, Denodo can be used to standardize and centralize common data cleansing and feature engineering tasks using its extensive transformation functions. Advanced or power users can take advantage of standard SQL and procedure languages instead to develop more complex and sophisticated business logic and data routines.
Leverage Logical Data View from Amazon SageMaker
Once a logical, analytical base table view has been developed, it can be used by BI users and data scientists via tools like Tableau or Notebooks-based data science solutions such as Amazon SageMaker Studio. Either way, business analysts or data scientists can discover and access the needed data views in seconds.
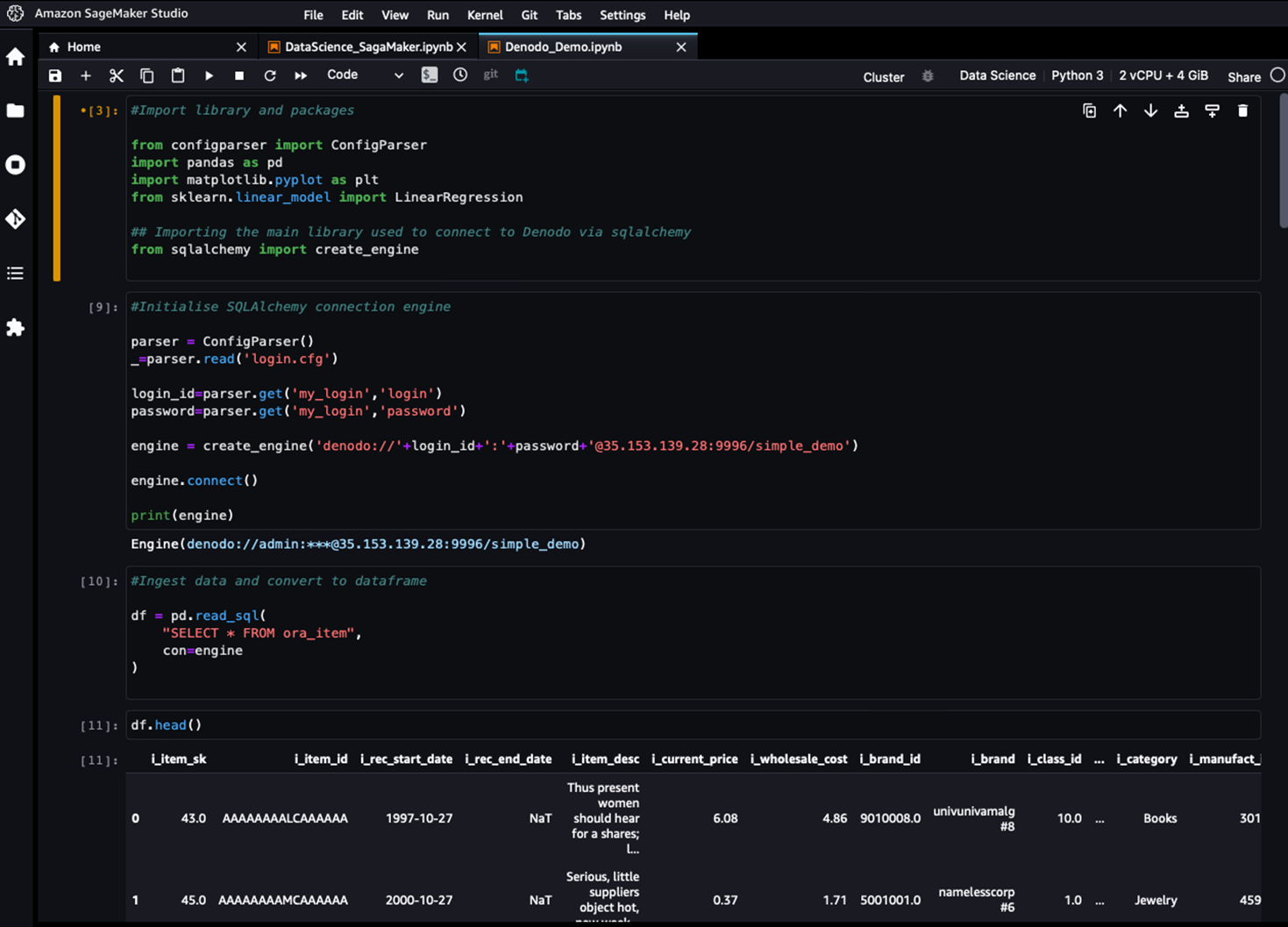
Figure 5 – Connecting to and retrieving data from Denodo using SageMaker Studio.
From the data scientist’s standpoint, new data sources can be integrated and leveraged quickly without waiting for the data engineering team or lengthy ETL development processes. Data lake files and API-based data services can also be connected and integrated without requiring any specialist skills.
From the IT and operations standpoint, exposing and publishing data via a logical layer means decreased data replication and a centralized location in which to implement data security and governance policies.
Conclusion
Denodo and data virtualization can minimize ETL and accelerate the data provisioning process for analytics projects. In a recent study, Forrester concluded that Denodo and data virtualization could deliver a 65% decrease in delivery times over ETL, resulting in shortened time to business insights.
When combined with AWS cloud services such as Amazon Redshift, the overall solution creates a potent solution for businesses looking to minimize ETL and accelerate their analytics effort. Denodo on AWS allows companies to be more agile and make real-time, data-driven decisions.
To experience the capabilities of Denodo with Amazon Redshift, sign up for a free trial offering on AWS that showcases functionality and performance capabilities. The Denodo Platform for AWS is available via subscription tiers:
- Denodo Professional is an entry-level subscription designed to help you get started with data virtualization.
- Denodo Standard provides data virtualization to your entire company.
- Denodo Enterprise and Enterprise Plus provide logical data fabric solutions that take data virtualization to advanced levels.
The Denodo user community provides a wealth of information along with case studies. To learn more, reach out to Denodo at [email protected].
.
.
Denodo – AWS Partner Spotlight
Denodo is an AWS Specialization Partner and leader in data management that’s focused on data virtualization technology.
Contact Denodo | Partner Overview | AWS Marketplace